
der Bibel
of the Bible
|
semantic field-Konkordanz der Bibel |
Semantic Field Concordance of the Bible |
Semantic Field Concordance- Help to handle the concordance
Es gibt auch eine deutsche Version dieses Hilfetextes. Sie können sie direkt aufrufen oder, indem sie zum Hauptmenue zurückgehen, mit dem «deutsch»-Befehl zur deutschen Sprache wechseln und den Hilfe-Befehl erneut aufrufen.
2.2. Methodology about operators for semantic fields and verse lists
3.1. Definition of the search run
3.1.3. Searching for exactly one word
3.1.4. Searching for a sequence of words
3.1.7. Documentation of all search runs
3.1.8. Context of a Bible verse
3.4.1. Character choice for searching
3.4.2. Character choice for text presentation
3.4.3. Documentation of search runs
3.4.5. Alignment of the Bible versions
3.4.6. Statistics of search of Bible verses
3.5. Show selection of Bible versions
3.5.3. Select only the first one
3.6. Navigation within the representation of results
The following table provides a quick survey. The subsequent text provides additional information.
| Operation | Unite | Intersect | Set difference |
| Logical eqivalent | OR | AND | AND NOT |
| Computing semantic fields | # | & | ~ |
| Computing verse lists | + | * | - |
| A space is interpreted * (logical AND) | |||
| Exactly one word | [faith] | provides the semantic field, which covers only the word «faith». | |
| Considering the order |
Jesus%Christ | Finds all verses in which a word from sematic field «Jesus» and a word from semantic field «Christ» occurs exactly in this order. | |
| The check mark «Semantic field covers only the word itself» |
Word field consists only of the defining word Effect: Like square brackets in all word field definitions |
Warning: This word fields are very small and averages of word fields are nearly meaningless. Caution. However, you can build a emantic fields word by word: Jesus#Jesu#Jesse provides a semantic field {Jesus, Jesu, Jesse}. |
|
The aim of this semantic field concordance is to provide a semantic field based word concordance.
The user should be able to create for his search a word list that contains exactly the words that he wants to search. Next he should have the opportunity to influence the verse list, by excluding verses that do not match his question.
But all questions are based on words or word lists. Long-term goal is to allow conceptual issues, but this is not yet possible.
2.2. Methodology about operators for semantic fields and verse lists
A sematic field based concordance is basically nothing new, because every concordance must decide whether there appear only Bible verses that contain exactly the word or whether declinations of the word are included. So if you search for "come", then you want to see also Matthew 24:27: For as the lightning cometh forth from the east, and is seen even unto the west; so shall be the coming of the Son of man. And when you read a translation which provides the current language, using "comes" instead of "comth", you want to find it as well.
To give the user a clear view about such issues, this concordance opens up the possibility to check semantic fields directly and decide whether they meet the target of the search or whether they need to be refined. Two levels of logical operations are provided: Operations at the level of semantic fields (# & ~) and operations at the level of verse lists (+ * -), which are derived from these semantic fields and represent the actual target of the search. There is the character %, which makes semantic fields and verse lists consider order.
If I search for the semantic field, derived from the word "love", I will realize that this semantic field also contains words like "cloven", which you probably do not want to look for, when interested in the semantic field of the word "love&ldquo. So you have to remove this word by defining a semantic field "love~clove". So I avoid verses like Leviticus 11,3: Whatsoever parteth the hoof, and is clovenfooted, [and] cheweth the cud, among the beasts, that may ye eat. in my verse list. This verse has nothing to do with biblical statements about love. In the command line, I should use "love~clove" instead of "love" alone.
if you do the same on the basis of verse lists, you write "love-clove". Then you get all verses, which show a word from the semantic field of love, but no word from the semantic field of "clove". If there were a verse in which both types of words exist, you would miss this verse. This is, why you have to distinguish carefully between operations for semantic fields (# & ~) and verse lists (+ * -).
It is important that you keep this difference clearly in mind: First, I need a carefully described goal for my search, the word field. Then I have to decide which verses I really want to see. I cannot do both in one step, because changes to the semantic field have a different effect than changes to the verse list, at least, as far as set difference is considered.
The example above clearly showed that I need operations to manipulate sematic fields. However, for other issues, you need operations, which manipulate verse lists. This is explained by another example:
Assume a search where you want to see all the verses in which Jesus is not called Christ at the same time. This I cannot achive by manipulating the semantic field of "Jesus". In fact, I have to search for all verses, containing a word from the semantic field of "Jesus". Then, I have to exclude all verses containing a word from the semantic field of "Christ". This, I can do, by entering "Jesus-Christ" into the command line. This is a set-theoretic operation. It should not be interpreted theologically.
You may argue that these semantic fields are not exactly the "semantic fields" of linguistics. You are right. But for me, it was the easiest way, to explain, what I wanted to do with these word lists.
The analysis is based the words which actually appear in the Bibel version under consideration. So a word will be included into a semantic field only, if the word actually appears in the Bible. If no such word exists, you will get the information that your semantic field is empty.
The Bible text is initially a verse list. The translations of American Standard Version of 1901 comprises 31 103 verses in 1 189 chapters and 66 books. The King James Bible includes Apocrypha. So it comprises 36 985 verses in 1 371 chapters and 81 books. These verse lists resolve into a list of words. This is done by dividing the characters on one side into letters and numbers, and on the other side into separating and control characters. Separating and control characters divide words. A word begins after a separation or control character and ends with the next separation or control character. In this way, American Standard Version of 1901 shows 13 475 different words, which appear 789 802 times. The King James Bible shows 15 384 different words, which appear 940 714 times.
Unfortunately, in the Chinese version, which I use, every character is followed by a blank. This means that the words with more than one syllable cannot be detected automatically. So, for this version, only characters (this means syllables) are available, no words. The user might use the operators for semantic fields, especially %, to enforce that a word is searched. [] is superfluous in Chinese Bible, because characters and words are identical.
I hope that colleagues which know the Arabic language will notice that my Arabic text can be correctly read from right to left. The verse number is on the right page. Sometimes this does not work and it appears the 39)) on the left side. An example can be provided only as a screen shot, because copied into this help everything looks correct. I'll work on it. Pertinent tips are welcome. Here the example of Acts 27, 39 as a copy:
(39) ولما صار النهار لم يكونوا يعرفون الارض ولكنهم ابصروا خليجا له شاطئ فاجمعوا ان يدفعوا اليه السفينة ان امكنهم.
and as a screen shot:

Using the link attributed to the verse "Acts of Apostles 27, 39", a window with the full chaper "Acts of Apostles 27" is shown. This allows to read the context of the verse for further studies.
Use the link, attributed to the verse number "27895", to return to the table of contents.
For each version of the Bible there is a transliteration. The transliteration is limited to ASCII characters, including having no umlauts. This enables every user, whatever keyboard is used, to define search runs in whatever language and characters. In the writings, which are based on the Latin alphabet, capital letters are replaced by lowercase characters and in German äöüÄÖÜß is replaced by aouaouss. This allows "Buch" and "Bücher" to be included in the search defined as "buch". Likewise, words are found that are witten in upper case in the beginning of a sentence and otherwise in lower case.
The transliteration of non-Latin fonts primarily serves the purpose to make these writings possible for keyboards, which do not support these characters. For this purpose, the scientific transliteration, which uses underlines and dots etc. is not useful. So, compromises had to be made. It was not the goal of creating a unique relationship between transcription and original letters. You loose this one-by-one relationship already, when you neglect capital letters. In Greek diacritics are ignored, the Hebrew, the vocalization was ignored.
Regarding Chinese characters the Pinyin spelling without sound is used as transliteration. As already mentioned above, each syllable represents a word. So, the Chinese script behaves completely different from the letter-based scripts. There are only 3017 words (syllables), but also as many characters. The fact that the sound is not regarded in transliteration reduces these to 416 Pinyin words. On average each Pinyin syllable corresponds to 7 different characters. However, there is one Pinyin syllable with even 50 characters which all match this single Pinyin syllable. This means that Pinyin syllables do not fully distinguish Chinese words. However, the distinction efficiency is increased in the practical work, since a search for words with several syllables reduces the verse lists significantly. This is at least my experience.
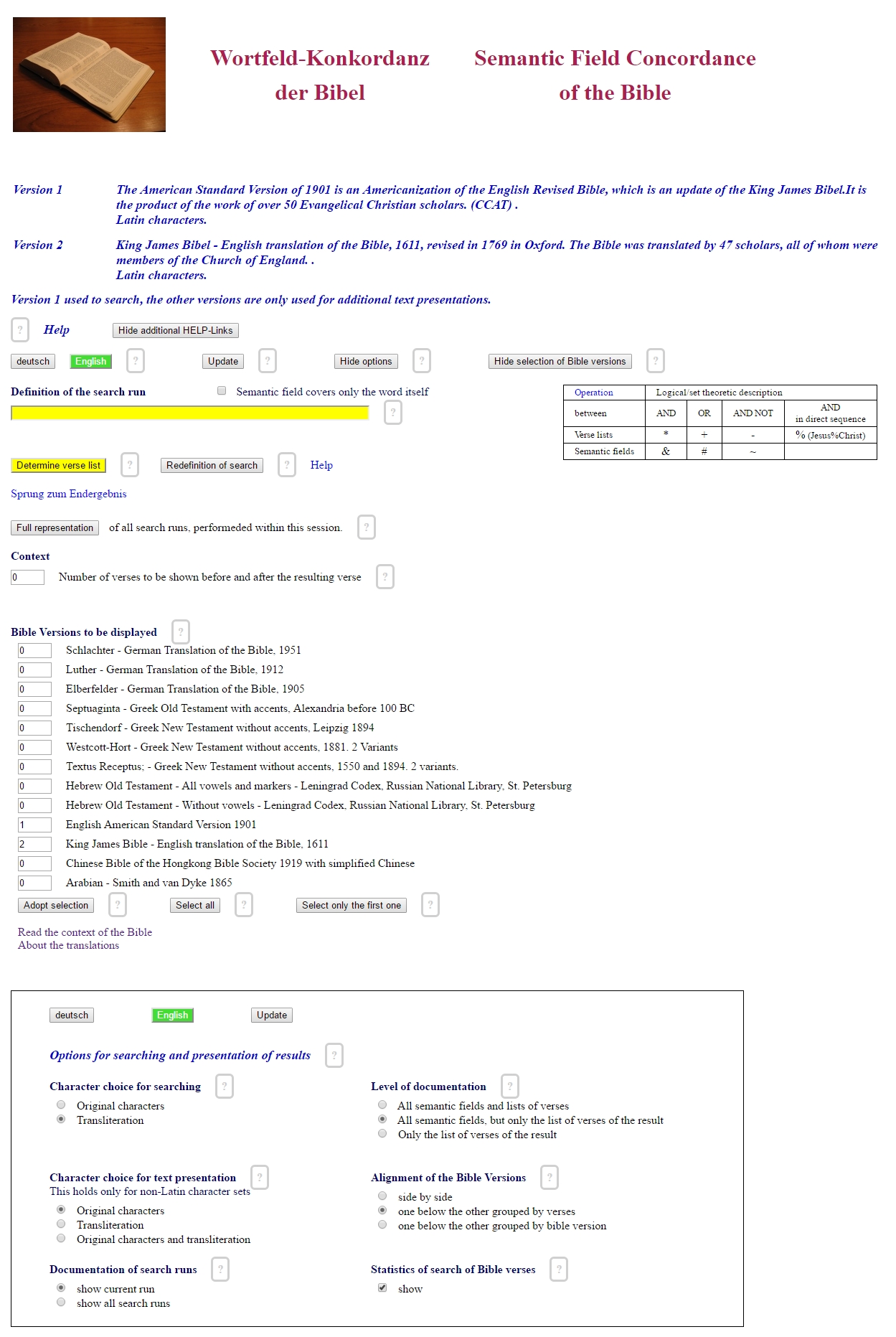
The settings that you need for productive work with the concordance are highlighted in yellow. All other settings are designed to meet your further requests to the type of input, the presentation or the selection of biblical texts as well as possible.
At the start of the concordance, you see the following picture:
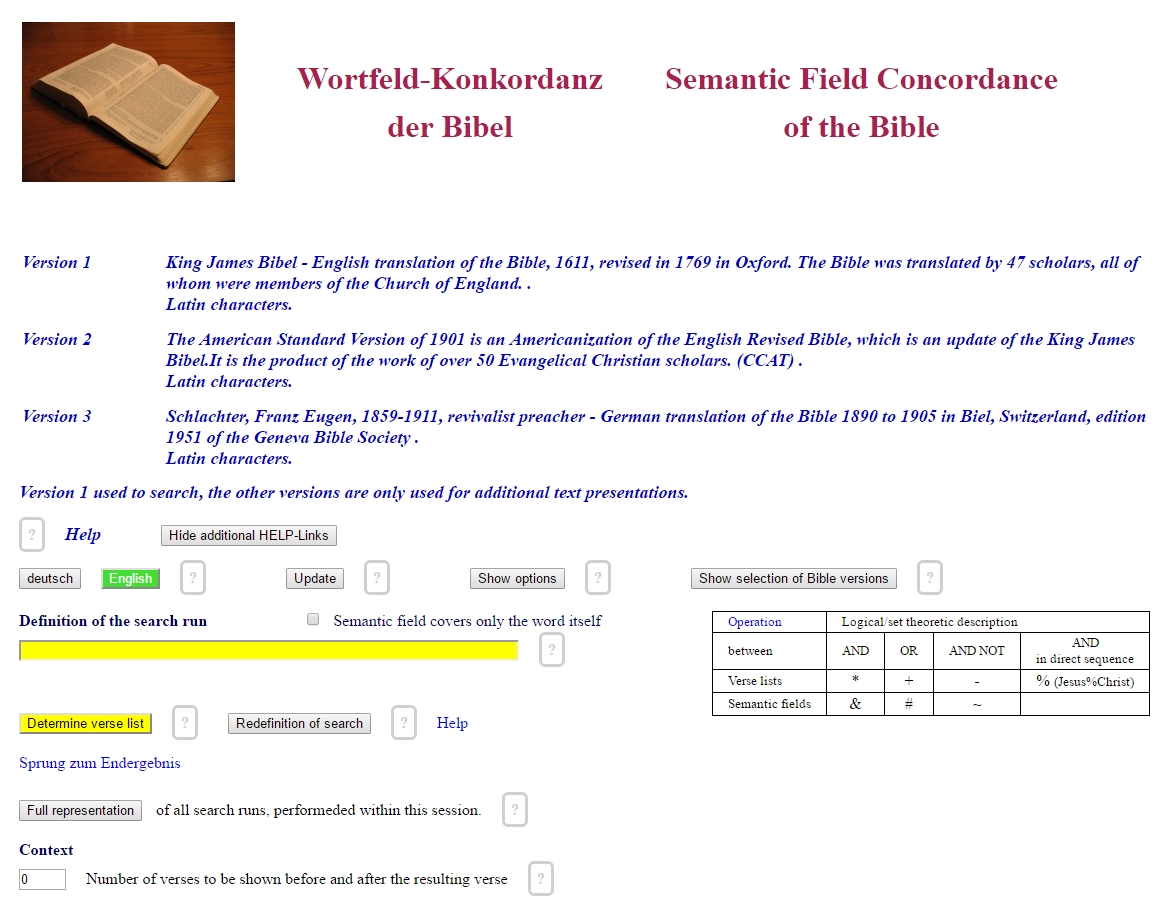
If it is in German, push the "English" button and language will switch to English.
3.1. Definition of the search run
Part of it is already explained in chapter 2. Objectives and methods. These examples show the various possibilities, which you have in defining a search run.
Entering the word "love" in the box under "Definition of the search", you get the semantic field:

Every word is followed by its transliteration (in parentheses). As option "Character choice for searching" we have chosen "Original letters", so, "Love" is not included in the list. The words are organized first by uppercase letters A..Z, then by lowercase letters a..z and then by umlauts ÄÖÜßäöü, if any exist. This does not change, even when looking at the transcript, as it is always ordered by the original letter. The order resulted from the codes of UTF8 encoding of character, so is not necessarily identical with the usual order of characters.
If you switch to button "transliteration" as option "Character choice for searching", you get a slightly longer list:

It is the same list like before, but now also including "Love" etc. with capital letter. You can do the same without the button "transliteration", if you search for "love#Love".
But sometimes, words are completely written with capital letters: E.g. "GOD" in King James Bible:
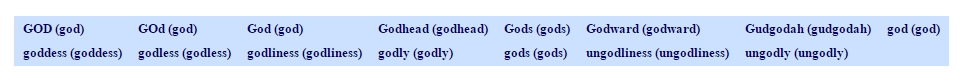
Using the transliteration, you even find the misspelled word "GOd".
The transliteration has some advantages for Latin characters, as well. Really relevant, it is for Greek, Hebrew, etc. Using the transliteration, you can formulate search runs with every key board, which supports ASCII-characters. If you have an Arabic key board, it should be possible, to formulate your search runs with Arabic characters as well. But I do not have such a key board, so I cannot test it. If you want to use original letters, make sure that your options are chosen accordingly: Option "Character choice for searching" checked for "Original letters".
Union: To unite semantic fields (logical OR), the character # is available. If you want to deal with Bible verses about love or hope, you may choose the search definition "love#hope". This creates a semantic field, which covers all words which include the letters love or hope.
Intersection: To intersect semantic fields (logical AND), the character & is available. If you try "love&hope", you will get the message: "This semantic field is empty.". There is no English word with the letters love and hope simultaneously.
Set difference: For the difference between two semantic fields (the logical AND NOT), choose the symbol ~. "love~clove" provides the semantic field, which you might expect for the word "love", because the words "cloven" and "cloven-footed" are excluded. If you look for "faith", you might in some cases prefer to exclude Unfaithful etc. You can do this by defining "faith~un".
Brackets: If you want to create a sematic field with "love", but without "cloven", but united with "hope", you may try "love~clove#hope". This does not work, because within brackets, only identical operations are allowed. So please use "(love~clove)#hope". This will work. Otherwise you receive an error message: "At one level only one operator is permitted." "love~(clove#hope)" creates a semantic field without the word "hope". So be careful, how you choose brackets. Everything is as you learned it in school.
In chapter 2.2. Methodology about operators for semantic fields and verse lists it was shown already that semantic field operations are not sufficient for all questions, you may have. Some questions need manipulations of the verse lists. The operations again are derived from logical operations, analogly to the approach for semantic fields. You have to consider that you always can derive verse lists from semantic fields, but the opposite is not possible with meaningful effort. This means that operations between semantic fields and verse lists are not possible at the same level. You have to compute the verse list from the semantic field and then you can execute the operation with the other verse list.
The operations:
Union: To unite verse lists (logical OR), the operation + is available. So you may generate from the verse list of semantic field "love" and the verse list of sematic field "hope" by "love+hope" a verse list that contains all the verses in which "hope" or "love" occurs. This is exactly the same verse list, which you create by the semantic field "love#hope".
Intersection: The intersection of two verse lists (logical AND) can be obtained by *. We mentioned in the previous chapter that the semantic field "love&hope" is empty. If you define a search run "love*hope", then you will find verses like Romans 5,5: And hope maketh not ashamed; because the love of God is shed abroad in our hearts by the Holy Ghost which is given unto us. Intersection of verse lists is a powerful tool, to define a search run, which provides exactly the verses, which you want to see.
Set difference: For the difference between two verse lists (logical AND NOT), choose the symbol -. The example "Jesus-Christ" was already mentioned before. This provides all verses, where the name Jesus is mentioned without his title Christ. "Jesus~Christ" provides the same like "Jesus", because no word in this semantic field includes the string "christ". Another example is "with~without". This is a semantic field, in which "with" occurs and without does not occur. A verse like 1.Peter 1,19: But with the precious blood of Christ, as of a lamb without blemish and without spot: will occur in the verse list, derived from this semantic field. The verse list "with-without" will not show this verse, because it is excluded from the verse list, due to the word "without". The verse list "with-without" is included into the verse list "with~without". But sometimes, "with~without" may provide more verses, the verses which show the words "with" and "without" simultaneously, are shown in addition.
Brackets: For brackets, the same holds as mentioned in the previous chapter. "Jesus-Christ+Lord" is rejected. "(Jesus-Christ)+Lord" and "Jesus-(Christ+Lord)" is accepted, but both provide different results. "(with~without)*blood" is accepted, "(with-without)*blood" also, but "(with-without)&blood" is not accepted, because "(with-without)" is a verse list and no longer a semantic field, due to the operation -. A verse field cannot be combined with a semantic field by a semantic field operation.
3.1.3. Searching for exactly one word
If you want to search for verses with the word "love", not for "loves" or other derivatives of this word, then you can do this by using square brackets: "[love]". If you checked "Original letters" in option "Character choice for searching", then even "Love" is omitted, if you checked "Transliteration", then "Love" is included as well. If you checked "Semantic field covers only the word itself", then the square brackets are not needed.
3.1.4. Searching for a sequence of words
When you look for a special verse of the Bible, you remember a sequence of words. You can make use of it: As an example John 3,16: For God so loved the world, that he gave his only begotten Son, that whosoever believeth in him should not perish, but have everlasting life. If you look for this verse, you might remember "For God so loved". So put in this phrase, only the words and % between the words (For%God%so%loved). The search will look for all verses, where the semantic fields of these words appear in exactly this order. If it would exist, "For our God so loved ..." would not be shown. So the answer will be John 3,16 and nothing else. To fasten the search run, you may check the button "Semantic field covers only the word itself", then the semantic fields are exactly the words, which you want to see.
This option is helpful for Chinese words with more than one syllable: As an example, we look for 黑%暗 or transliterated "hei an", the Chinese word for "darkness". This run will include "谁%敢", or "shei%gan", since "shei" is part of semantic field "hei" and "gan" part of semantic field "an". This means "Who dares" and has nothing to do with our search run. You can avoid this by writing "[hei]%[an]" or by using the check box "Semantic field covers only the word itself".
When you define the search run according to the rules, given above, then you switch button "Determine verse list", to start the search.
Be aware that the quotation marks are used, to indicate the input text, but they are not part of the input text.
This button clears the input of "Definition of the search run". You may start a new search run. The previous text will be deleted. If you want to keep the previous result, copy it to the clipboard. You may use the text elsewhere, but be aware that it is UTF8 text.
3.1.7. Documentation of all search runs
This switch presents everything you've created so far in your session. Each search is displayed, a complete overview of your work. But it may occur after a long session that this is too much for my provider or your computer and one of them or both may refuse to work and nothing is displayed. Should this occur, then you close your Internet browser and start a new calculation. The old search runs are lost, unfortunately, because my provider releases the memory in such a case. This is not under my control.
3.1.8. Context of a Bible verse
Occasionally verses are very short and you do not recognized immediately the context. You may define an environment of verses to see the context via the input line "Number of verses to be shown before and after the resulting verse". If you enter a "1", a verse in front and a verse after the reference is provided additionally. The verse numbers coincide in most versions. However, I am not able to verify this in detail. If shifts occur, this option provides a way to choose a larger textual context in order to compensate deviations in parallel versions. If you notice discrepancies, I am grateful for information.
[love] |
searches exactly the word "love", generates a semantic field with the word "love" and nothing else. "Love" will be ignored as well, if within option "Character choice for searching" "Original characters" is selected. |
love |
generates a semantic field with |
love~clove |
generates a semantic field with all words, containing the string "love", but not containing the string "clove", it excludes cloven (cloven), clovenfooted (clovenfooted) from above. |
faith~un |
generates a semantic field with "faith", but excludes all negative derivatives like "unfaithful". |
faith~un~faithless |
~ provides a method, to exclude special words from the semantic field. |
faith&un |
generates a semantic field with "faith", but only the negative derivatives: unfaithful (unfaithful), unfaithfully (unfaithfully), unfaithfulness (unfaithfulness). |
faith#un |
generates a semantic field with "faith" and all words, containing the string "un", these are 426 words. This search will find half of the Bible, 14 237 of 37 035 verses. |
faith*hope*charity |
looks for all verses, in which "faith", "hope", and "charity" appear at the same time. This is exactly 1.Corinthians 13, 13, if you search within King James Bible. If you use American Standard version, you should search for "faith*hope*love" and you will find 1.Corinthians 13, 13, 1.Thessalonians 1, 3, and 1.Thessalonians 5, 8. |
(faith*hope)+(faith*love)+(hope*love) |
this provides a possibility to look for at least 2 of the 3 words faith, hope, love in one verse. This occurs in 48 verses of the American Standard version, 46 of them in the New Testament, 37 in letters of Paul. |
For God so |
provides all verses with the sequence "For God so" in this order. The result depends on the check box
"Semantic field covers only the word itself". If checked, you only find John 3,16:
For God so loved the world, that he gave his only begotten Son, that whosoever believeth on him should not perish,
but have eternal life. |
jesus%christ |
provides all verses, where "Jesus Christ" is mentioned. You will miss the verse Revelation 20, 4: And I saw thrones, and they sat upon them, and judgment was given unto them: and [I saw] the souls of them that had been beheaded for the testimony of Jesus, and for the word of God, and such as worshipped not the beast, neither his image, and received not the mark upon their forehead and upon their hand; and they lived, and reigned with Christ a thousand years. This verse, you only get, when searching "Jesus*Christ". |
jesu christ |
provides the same. |
jesu-christ |
provides all verses with "Jesus", but without his title "Christ". |
Chapter 3. Methods and settings shows the input menu with the green button "English". This means that the language of the menue is English. You may switch to German by the grey button "deutsch". Then the colors will change and the menue is in German. The Bible versions, which you selected, are not changed by these buttons. When you use one of these buttons, your representation of results is cleared as well. You can recover it by using button "Update" (see 3.3). You will see the results of the update or of the next search run in the selected language. The Bible text is not changed, it only depends on your choice of Bible versions.
Note: The selection of Bible versions is not affected. The definition of search runs has to be made in the language of your version 1.
When you changed settings and want to apply them, use button "Update". E.g. When you changed the language and want to recover it, you can do it by this button.
This button "Show options" opens an additional area of the menu to allow different settings. Sometimes, in 3.2, we referred already to these settings. When you use this button, its label changes to "Hide options". When you switch "Hide options", the additional area disappears again. This keeps your working area clear.
The options will be described below. The button "deutsch", "English", and "Update" do the same as the buttons with the same name outside of the options area.
All settings, which you make here, influence your further session, even the representation of the Bible text.
When the button "Show options" is switched, your working area looks like this:
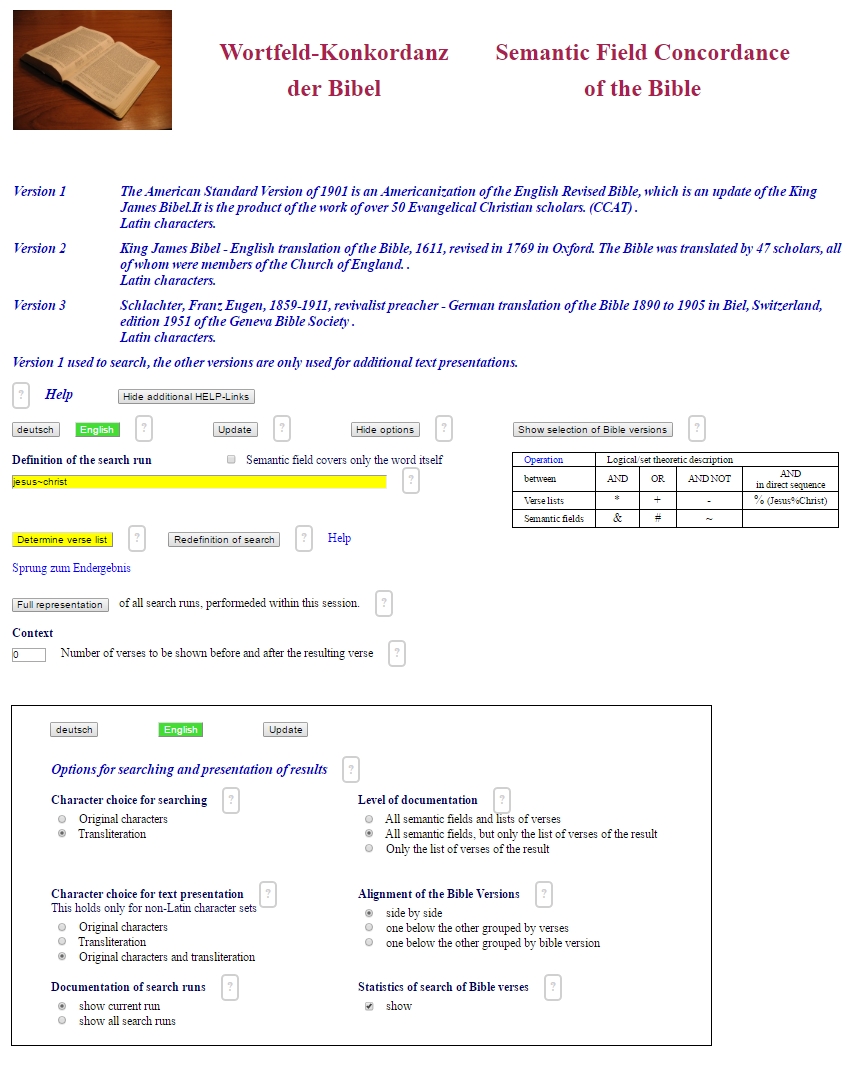
When you start a new session, you will find default settings. This is, why the program runs without cookies and without "login".
3.4.1. Character choice for searching
When discussing semantic fields (3.1.1.) and search runs (3.1.3.), the different effect of original letters and transliteration, even with latin letter based characters, was mentioned. This is the point, where you can choose your setting.
Latin character based languages allow neglectance of capital letters. In German, you find in addition that "ÄÖÜäöüß" is substituted by "aouaouss". In Greek, Hebrew, Chinese, or Arabic languages, transliteration allows, to write search runs with a ASCII key board. This is the main goal of this transliteration. Words are not identified without ambiguity by the transliteration. Every original word has exactly one transliteration, but not vice versa. The following table shows the degree of ambiguity, which you have, when you look for original words which correspond to one transliteration word:
| Characters | Number of | Same transliteration | Original /Transliteration | |||||||
| Version | Basis | Original words | Transliterated words | Appearance | 2 | 3 | 4 | 5 | >5 | Ratio |
| Schlachter schl | Latin | 28 451 | 25 938 | 711 881 | 2 285 | 90 | 16 | 0 | 0 | 1.097 |
| Luther lu12 | Latin | 22 242 | 20 024 | 699 678 | 2 017 | 84 | 11 | 0 | 0 | 1.111 |
| Septuaginta lxxa | Greek | 47 779 | 44 230 | 601 236 | 3 056 | 207 | 19 | 2 | 2 | 1.080 |
| American Standard Version asvb | Latin | 13 475 | 12 337 | 789 802 | 1 094 | 22 | 0 | 0 | 0 | 1.092 |
| King James Bible kija | Latin | 15 384 | 14 189 | 940 714 | 1 146 | 23 | 1 | 0 | 0 | 1.084 |
| Chinese Bible: Hongkong-Bible-Society chus | Chinese | 3 017 | 416 | 929 275 | 44 | 34 | 36 | 26 | 217 | 7.252 |
| Smith and van Dyke arab | Arabic | 57 040 | 56 218 | 435 153 | 758 | 32 | 0 | 0 | 0 | 1.015 |
This table was provided to show the degree of separation, provided by transliteration. The special situation with the Chinese Bible was already mentioned (2.4.)
3.4.2. Character choice for text presentation
You may choose, whether you want to see the text of the Bible in original letters or in transliteration or in both ways. This choice only effects the presentation of the text, not the search run. For search run, see 3.4.1.
3.4.3. Documentation of search runs
Here, you have the opportunity, to make a complete documentation of all your search runs of you session. In 3.1.6., it was already mentioned that this might be too much for the involved computers, if you had a very long session.
This setting only holds for one search run, it is restored to "show current run" after "show all search runs" is performed. All other settings hold for your session, as long as you do not change them.
If you want to make a quick search run, it is advisable to choose "Only the list of verses of the result". Then you get your list of verses and will not be bothered with further information. If you are you interested in the semantic fields, as well, which were basis of the result, then select "All semantic fields, but only the list of verses of the result". If you have verse list operations in the definition of your search operation, the origin of the resulting verse list can be interesting, especially if the resulting verse list is empty. In order to achieve this, select "All semantic fields and lists of verses". In particular, in the latter case, you are bombarded with a plethora of lists. To may navigate within these lists, there are some jump addresses that you should try out. For an explanation, see 3.6.
3.4.5. Alignment of the Bible versions
Basically, you can may choose "side by side", because it is clearer. You will see the various versions, you selected, for every verse side by side:
| ||
(24) Dem aber, welcher mächtig genug ist, euch ohne Fehl zu bewahren und euch unsträflich, mit Freuden vor das Angesicht seiner Herrlichkeit zu stellen, | (24) Dem aber, der euch kann behüten ohne Fehl und stellen vor das Angesicht seiner Herrlichkeit unsträflich mit Freuden, | (24) Now unto him that is able to guard you from stumbling, and to set you before the presence of his glory without blemish in exceeding joy, |
(25) Gott allein, unsrem Retter durch Jesus Christus, unsren Herrn, gebührt Herrlichkeit, Majestät, Macht und Gewalt vor aller Zeit, jetzt und in alle Ewigkeit! Amen. | (25) dem Gott, der allein weise ist, unserm Heiland, sei Ehre und Majestät und Gewalt und Macht nun und zu aller Ewigkeit! Amen. | (25) to the only God our Saviour, through Jesus Christ our Lord, [be] glory, majesty, dominion and power, before all time, and now, and for evermore. Amen. |
(Offenbarung 1, 1) Offenbarung Jesu Christi, welche Gott ihm gegeben hat, seinen Knechten zu zeigen, was in Bälde geschehen soll; und er hat sie kundgetan und durch seinen Engel seinem Knechte Johannes gesandt, | (Offenbarung 1, 1) Dies ist die Offenbarung Jesu Christi, die ihm Gott gegeben hat, seinen Knechten zu zeigen, was in der Kürze geschehen soll; und er hat sie gedeutet und gesandt durch seinen Engel zu seinem Knecht Johannes, | (Offenbarung 1, 1) The Revelation of Jesus Christ, which God gave him to show unto his servants, [even] the things which must shortly come to pass: and he sent and signified [it] by his angel unto his servant John; |
However, this is only recommended for a small number of selected versions, otherwise the columns are too narrow, and your Internet browser occasionally makes very strange formatting. Therefore, there is also the possibility to arrange the versions one below the other. You have the choice between "one below the other grouped by verses" and "one below the other grouped by bible version". If you have chosen 0 for "Context", you will see no difference between the two variants. If, however, you have chosen 1 or more for "Context", you will see a difference between the two variants. Easier than an explaination is an example.
Example for "one below the other grouped by verses":
| |||
| |||
| |||
|
Every verse is a group of three versions of the text.
In the next example you see "one below the other grouped by Bible version":
|
(24) Dem aber, welcher mächtig genug ist, euch ohne Fehl zu bewahren und euch unsträflich, mit Freuden vor das Angesicht seiner Herrlichkeit zu stellen, (25) Gott allein, unsrem Retter durch Jesus Christus, unsren Herrn, gebührt Herrlichkeit, Majestät, Macht und Gewalt vor aller Zeit, jetzt und in alle Ewigkeit! Amen. (Offenbarung 1, 1) Offenbarung Jesu Christi, welche Gott ihm gegeben hat, seinen Knechten zu zeigen, was in Bälde geschehen soll; und er hat sie kundgetan und durch seinen Engel seinem Knechte Johannes gesandt, |
(24) Dem aber, der euch kann behüten ohne Fehl und stellen vor das Angesicht seiner Herrlichkeit unsträflich mit Freuden, (25) dem Gott, der allein weise ist, unserm Heiland, sei Ehre und Majestät und Gewalt und Macht nun und zu aller Ewigkeit! Amen. (Offenbarung 1, 1) Dies ist die Offenbarung Jesu Christi, die ihm Gott gegeben hat, seinen Knechten zu zeigen, was in der Kürze geschehen soll; und er hat sie gedeutet und gesandt durch seinen Engel zu seinem Knecht Johannes, |
(24) Now unto him that is able to guard you from stumbling, and to set you before the presence of his glory without blemish in exceeding joy, (25) to the only God our Saviour, through Jesus Christ our Lord, [be] glory, majesty, dominion and power, before all time, and now, and for evermore. Amen. (Offenbarung 1, 1) The Revelation of Jesus Christ, which God gave him to show unto his servants, [even] the things which must shortly come to pass: and he sent and signified [it] by his angel unto his servant John; |
Every version forms a group of three verses, as requested by "Context".
3.4.6. Statistics of search of Bible verses
Together with the verse list, a table is provided that indicates the frequency with which the search result appears in the Bible, in the book groups such as NT and OT etc and in the individual books. In these statistics, verses in which the word appears several times are counted only once. To evaluate the result, another column shows the number of verses of the book group or the book. The book name is linked with the first appearance of a verse of this book in the verse list. This helps to find the verses of this book more quickly.
If you checked "show" for "Statistics of search of Bible verses", then you will find detailed statistical information. Instead of two, you will now find 6 columns of the matrix of statistics. The meaning of the columns is described in the following table:
| Note: Within these statistics, "incidence" always means "a verse, in which a search result occurs". A multiple occurrence within one verse is always counted as one incidence. | |
| Column | Explaination |
| Name of the book | The book or the group of books, for which the statistical information is provided. |
| Incidence (abs.) | The incidence in absolute numbers in the specified group or book of the Bible. |
| Share of all incidences | 100% in this column means:
All incidences occur in the specified group or book of the Bible (in the example "abimelech" 62 incidences). An incidence is related to all incidences, neglecting the length of the book. This column shows the breakdown of incidences on the Bible. In the example "abimelech", an incidence corresponds to 1.672% (=100%/62). This column guides you to find, where your incidence occurs. |
| Incidence (% of verses of Bible) | 100% in this column means: All the Bible verses show the incidence (in the example "abimelech" 31102 Bible verses).
This is nearly impossible. This column refers the number of incidences to the total number of Bible verses, generally 31102 verses. This column is proportional to the two columns in front of it. 1 incidence of the column "Incidence (abs.)" corresponds to 0.0032% in this column. The different length of the books is still ignored here. This normalization is carried out in the next column. The column may provide a warning, not to overestimate the preceding column, if these figures are very small. |
| Incidence (% of verses of book) | 100% means that the incident occurs in all verses of the specified group or book of the Bible. In this column, the number of incidences is related to the number of verses of the specified group or book of the Bible. In the example "abimelech", the 23 incidents are related to the 1533 verses of Genesis, this results in 1.5003%. The 36 occurrences in the book of Judges in contrast are based on only 618 verses of the book of Judges and provide 5.8252%, an almost 4 times greater frequency of the incidence in Judges than in Genesis. Here the comparison is made, which includes the number of verses of a book into the evaluation. This enables to identify books in which a particular word has a particularly strong relevance. For this purpose, you also have to look into the list of books, in which the incidence does not occur. These figures do not add up to 100% because each number has a different reference value. It is interesting to check, whether this column is homogeneous or varies greatly. Homogeneity will be expected for words which are necessary for linguistic and grammatical reasons (eg "the"). Strong fluctuations is to be expected for words which have a special meaning (like "grace"). A measure for this variation is scattering. The data obtained were related to the mean value, the column value for the entire Bible (in the example 0.1993%). The deviations were weighted by the book size. If you recalculate it, please note that in the table all the books with 0% have been omitted, but have to be included into the calculation of scattering. |
| Incidence related to the average of the Bible | 100% in this column means that the incidences in the specified group or book of the Bible are as frequent as
in the whole Bible (as on average). The ratio of the value of preceding column for the specified group or book of the Bible and the same value for the whole Bible is computed. Figures show more than 100%, if the incidence is more frequent than on average of the Bible. Figures show less than 100%, if the incidence is less frequent than on average of the Bible. The column provides no additional information, but it makes it more convenient, to look for books, which are most interesting for the incidence, you are looking for. |
| Total number of verses | The last column is only informal, it shows the number of verses of the specified section or book of the Bible. Thus, you are able to recalculate all the columns and to check whether the program calculates everything correctly. If you have found any errors, I would be grateful for a reference. In this case, I would like to know, in what Bibelversion you made your inquiry and what the inquiry and the error was. |
| Last row: The scattering, described within column "Incidence (% of verses of book)" is provided in the last row, entitled "Statistical deviation" You find the absolute value and the percentage, related to the average of the Bible. |
|
| Below the statistics table: You find the list of all books of the bible version with no incidence. Books are only listed, when they exist in the search version of the Bible. If you search within a version, which includes the Apogrypha, then Apogrypha books are listed, if they show no incidence. If Apogrypha do not exist in your version, then they will not be listed in this list. |
|
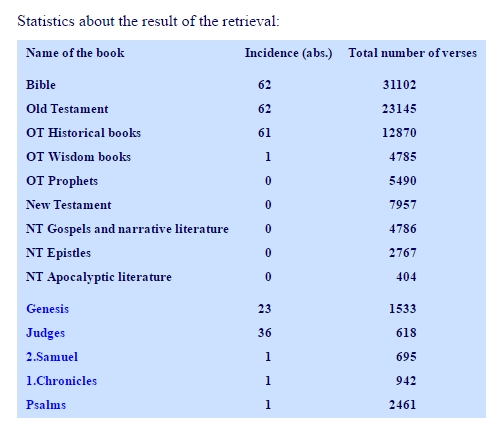
The following figure shows the complete statistics information for search run "abimelech", which refers to a king of the Philistines:
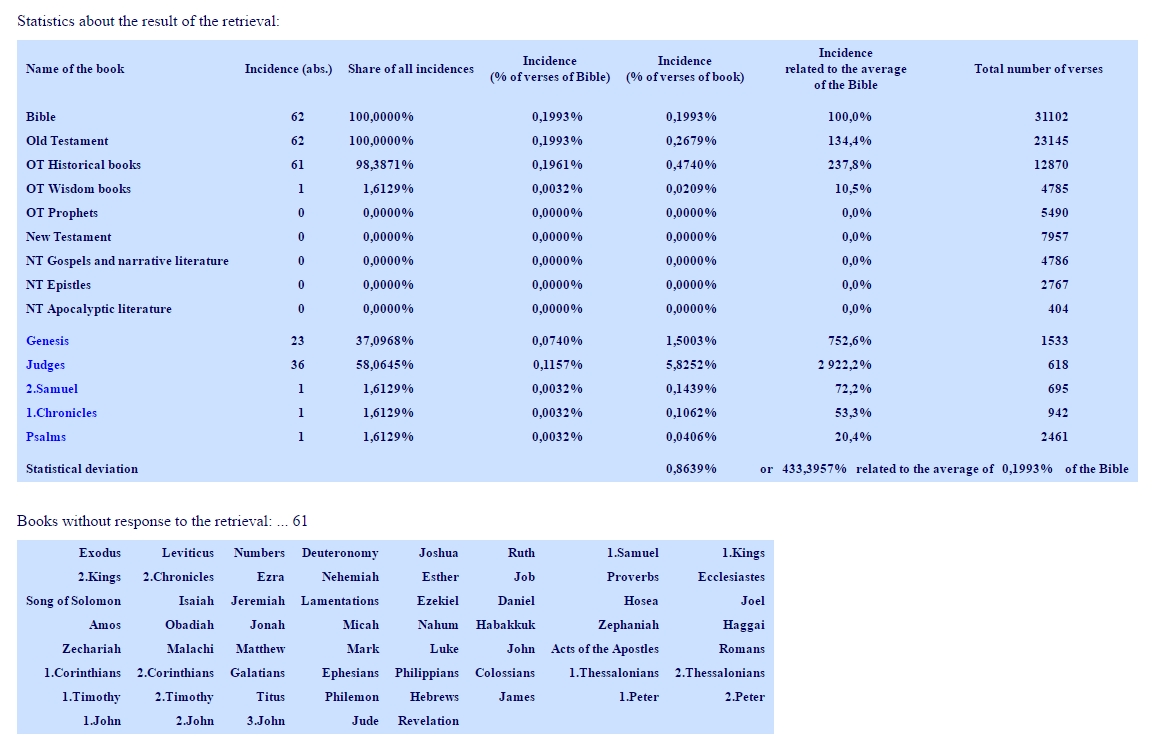
The name "Abimelech" refers only to Philistine kings and is mentioned only in the Old Testament, but in 62 verses. Related to the 32 102 of the Bible, this means 0.1993% of all verses. This is the average or mean value for the incidence of "abimelech". Incidence means the occurrence in one verse. Multiple occurrences in one verse are counted as 1 incidence. In Genesis, we find 23 incidences or 37.0968% of all incidences, but only 1.5003% of the verses of Genesis show an incidence. This is a value of 752.6% of the 0.1993%, which we found for the whole Bibel, 7.5-times as much as on average.
36 incidences, we find in the book Judges, 58.0645% of the incidences. But this means 5.8252% of the verses of Judges, 2922.2% of the value for the Bible or 29.2-times more. The scattering is 0.8639%, this is 433.3957% of the average of 0.1993%, a very high scattering, a consequence of the fact that the incidence does not occur in 61 books (Apogrypha not included, because they are not part of the American Standard Version of 1901, as used here in this search run.
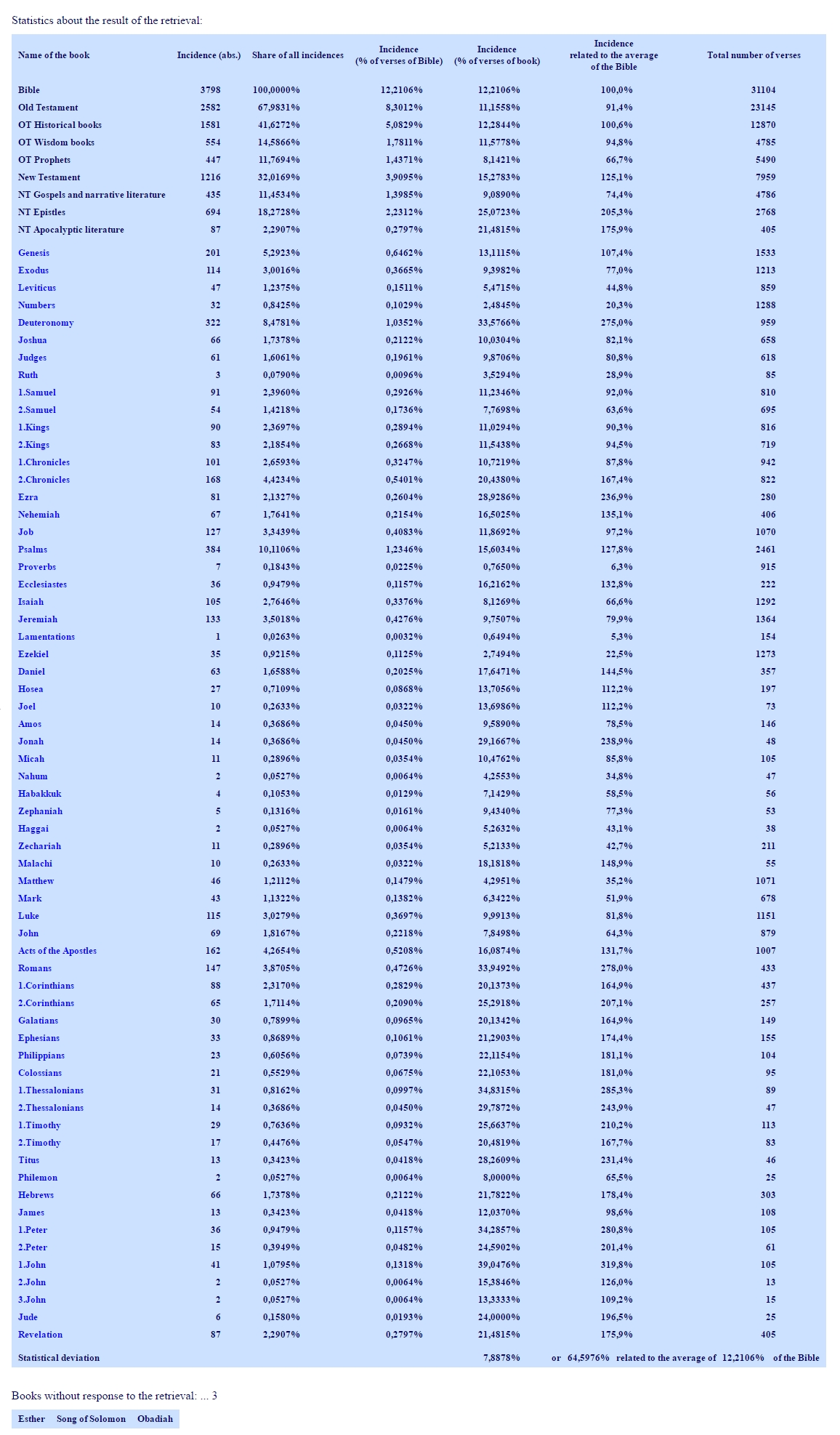
As a comparison, the search run for "god" is shown in the following figure. The incidences show different frequencies, when we compare the books of the Bible. But they are much more equally distributed than search run "abimelech". Only three books of the Bible miss this word completely: Esther, Song of Salomon, and Obadiah. The statistical deviation of 7.8878% seems much higher than for "abimelech" (0.8639%), but related to the much higher average of 12.2106%, they are in fact only 64.5976% of this average. For "abimelech", we found 433.3957%.
You may wonder, why the data are provided with so much digits. This is, because I cannot forsee, what results different search runs may provide, sometimes small numbers, sometimes bigger. Fixed formats are an advantage, because you get used to it. In some cases, you really need this precision, to understand that a figure is not exactly zero.
The examples provided shall show that statistical information do help to evaluate the search result. They are not an attempt, to avoid the work with the context itself. They are not able to decide about authors of the text or whatever people try to do to get rid of the message of challenging passages of the Bible. But they help to understand, where in the Bible special topics are discussed and where not. So they are foot notes, to find emphases of authors and also white spots for them. The full Bible is the word of the living God, the Old Testament read with the eyes of the New Testament. All authors of books are servants for the great saving grace of God.

3.5. Show selection of Bible versions
When you start your session, only Bible version 1 is selechted.
The button "Show selection of Bible versions" opens an area of the window, which offers all available Bible versions for selection. When you push this button, the caption of the button changes into "Hide selection of Bible versions". You may use this after finishing the Bible version selection, to keep your working space clear.
The Bible versions are selected, when you put a positive number (>0) into the input box in front of the name of the Bible version. The value of the number controls the order of the Bible versions. When you have no preferences for the order, you may also enter other characters besides "-". Be careful with the choice of number 1, because this will be the version, which is used within the search run. The incidences, found in #1, will be shown in all selected versions. The language, which you use to define the search run, must be the language, character or transliteration, of version 1. If you do not define #1, the lowest number will become #1, the next will become #2 etc.
When you enter a "-", then the respective version will be deselected. It does not matter if you enter the "-" before or after or instead of the existing value. After adopting the selection, you will always find a "0" at this place.
This is the button, which makes the program read and adopt your selection. The numbers will always be 1, 2, 3, ... even if you enter 2, 4, 6, ... The version list at the top of the page will be adapted accordingly. You may skip pushing button "Adopt selection" and directly start a new search run with button "Determine verse list". This will also adopt the new selection.
Whatever you do, the old search run will be deleted, because the Bible versions of the result no longer fit to your request. If you want to see the old results again with the new selection, start your search run again. In this case, it may help to keep your search run input in the clipboard, while changing the selection.
This button selects all Bible versions in the order, in which they are in the database. This new selection is adopted implicitly.
3.5.3. Select only the first one
This button selects only the first version and deselects all other versions. This new selection is adopted implicitly.
3.6. Navigation within the representation of results
The presentation of the results can be very comprehensive, depending on your choice. This is why several jumps are included, to support navigating within the results. If you are only interested in the final result, which is the final verse list, then use "Jump to the final result" or your keyboard button "end". There you find the final verse list. If you want to check, how the result is computed, then the jumps will support it.
Some words about the concept of the final result:
Instead of a long description of the jumps, a flow chart, which gives an idea, how the jumps are organized. Try it, to get familiar with them.
At first the jumps within the semantic fields. For verse lists, it is organized analogously:

The jumps within the verse lists provide a simple access to the search results of particular books of the Bible:

You might be disappointed that you cannot save the results directly. This chapter will provide some tips, how you can do this:
You may select the part of the verse list, which you want to save. You copy the selected text and paste it into an appropriate word processor, e.g. MS-WORD or the OPEN-OFFICE-WRITER. If you try to copy the table with the statistics information as well, MS-WORD will show rather poor results, OPEN-OFFICE-WRITER will show an acceptable copy.
For the statistics tables, screenshots might be used, to integrate them into MS-WORD as a graphics file (*.jpg). OPEN-OFFICE-WRITER will support direct copy and paste, even for the tables.
You get better results, when you use MS-EXCEL and paste your text into MS-EXCEL. But you have to adjust the width of the columns of the EXCEL-tables, to make the text readable. OpenOfficeCalc adjusts the column-width automatically and uses "merged cells". It needs less user activities, to show a readable text. Try it and make your choice.
There are better solutions for this purpose, but these solutions mean that either you save your data on my server, which means login etc. or I save them as cookies on your computer. I want to avoid this, because it causes other problems. My goal is, to support you in studying God's Holy Word and I am sure that it will bless you.
If you have problems, please feel free and send me an e-mail:
My e-mail account is rz@preach-the-word.net